Cloud architecture
Setup Docker in Ubuntu 14.04
10/09/14 16:51
Overview
We are entering an age of open cloud infrastructure and application portability. The applications/services are required to scale in/out as per demand and need to be executed in multiple host environment. For this applications are required to run within shell, and the shell/container needs to work across several hosts and be portable to any cloud environment.
Docker is a container-based software framework for automating deployment of applications, makes it easy to partition a single host into multiple containers. However, although useful, many applications require resources beyond a single host, and real-world deployments require multiple hosts for resilience, fault tolerance and easy scaling of applications.
Installtion
These instructions describe to setup latest version of Docker for Ubuntu 14.04 for not latest release from Docker. Following are the list of commands.
To setup latest Docker release, add the Docker repository key to your local keychain and process the install commands
After install the Docker you can search any community containers. For e.g if you need to search for any debian package,
We are entering an age of open cloud infrastructure and application portability. The applications/services are required to scale in/out as per demand and need to be executed in multiple host environment. For this applications are required to run within shell, and the shell/container needs to work across several hosts and be portable to any cloud environment.
Docker is a container-based software framework for automating deployment of applications, makes it easy to partition a single host into multiple containers. However, although useful, many applications require resources beyond a single host, and real-world deployments require multiple hosts for resilience, fault tolerance and easy scaling of applications.
Installtion
These instructions describe to setup latest version of Docker for Ubuntu 14.04 for not latest release from Docker. Following are the list of commands.
- sudo apt-get update
- sudo apt-get install docker.io
- sudo ln -sf /usr/bin/docker.io /usr/local/bin/docker
- sudo sed -i '$acomplete -F _docker docker' /etc/bash_completion.d/docker.io
To setup latest Docker release, add the Docker repository key to your local keychain and process the install commands
- $ sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv-keys 36A1D7869245C8950F966E92D8576A8BA88D21E9
- $ sudo sh -c "echo deb https://get.docker.io/ubuntu docker main > /etc/apt/sources.list.d/docker.list"
- $ sudo apt-get update
- $ sudo apt-get install lxc-docker
After install the Docker you can search any community containers. For e.g if you need to search for any debian package,
- docker search debian
Reliability design for Cloud applications
23/07/14 17:26
On of the backbones of the software reliability is avoiding the faults. In software reliability engineering, there are four major approaches to improve system reliability.
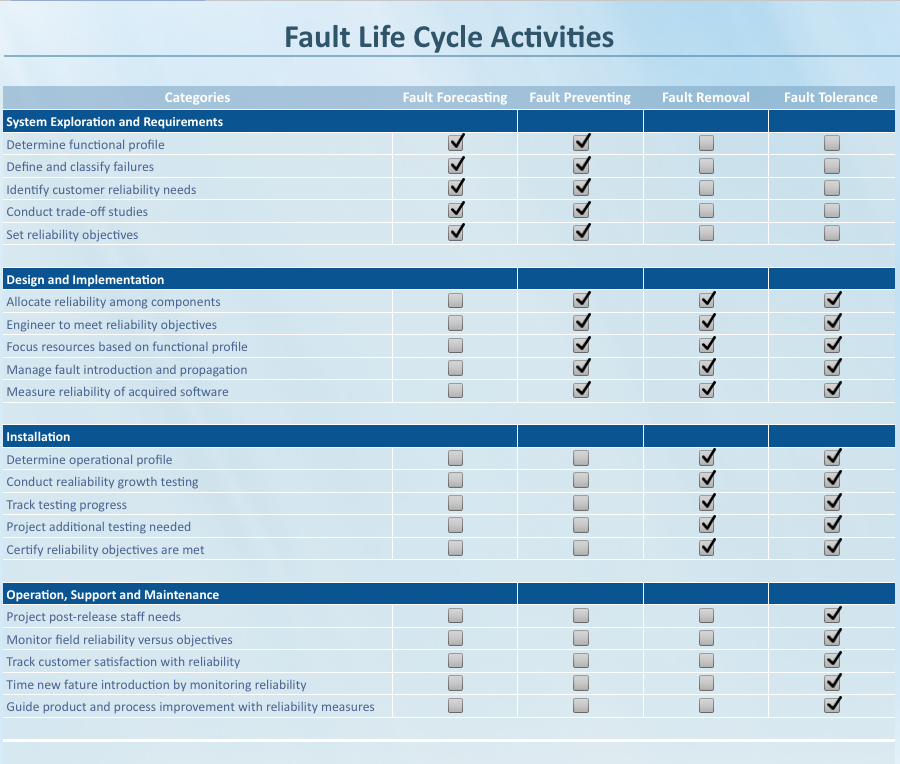
When changing to the cloud environment, the applications deployed in the cloud are usually distributed into multiple components, only having fault prevention and fault removal techniques are not sufficient. Another approach for building reliable systems is software fault tolerance, which is to employ functionally equivalent components to tolerate faults. Software fault tolerance approach takes advantage of the redundant resources in the cloud environment, and makes the system more robust by masking faults instead of removing them.
Cloud computing platforms typically prefer to build reliability into the software. The software should be designed for failure and assumes that components will misbehave/fail or go away from time to time. Reliability should be built into application and as well as data. I.e. within the component or external module should monitor the service components and provide/execute recovery process. Multiple copies of data are maintained such that if you lose any individual machine the system continues to function (in the same way that if you lose a disk in a RAID array the service is uninterrupted). Large scale services will ideally also replicate data in multiple locations, such that if a rack, row of racks or even an entire datacenter were to fail then the service would still be uninterrupted
- Fault Forecasting: Provides the predictive approach to software reliability engineering. Measures of the forecasted dependability, can be obtained by modelling or using the experience from previously deployed systems. Forecasting is a front-end product development life cycle exercise. It is done during system exploration and requirements definition. Fault prevention: Aims to prevent the introduction of faults, e.g., by constraining the design processes by means of rules. Prevention occurs during the product development phases of a project where the requirements, design, and implementation are occurring.
- Fault removal: Aims to detect the presence of faults, and then to locate and remove them. Fault removal begins at the first opportunity that faults injected into the product are discovered. At the design phase, requirements phase products are passed to the design team. This is the first opportunity to discover faults in the requirements models and specifications. Fault removal extends into implementation and through installation.
- Fault tolerance: Provides the intrinsic ability of a software system to continuously deliver service to its users in the presence of faults. This approach to software reliability addresses how to keep a system functioning after the faults in the delivered system manifest themselves. Fault tolerance relies primarily on error detection and error correction, with the latter being either backward recovery (e.g., retry), forward recovery (e.g., exception handling) or compensation recovery (e.g., majority voting). From the middle phases of the software development life cycle through product delivery and maintenance, reliability efforts focus on fault tolerance.
When changing to the cloud environment, the applications deployed in the cloud are usually distributed into multiple components, only having fault prevention and fault removal techniques are not sufficient. Another approach for building reliable systems is software fault tolerance, which is to employ functionally equivalent components to tolerate faults. Software fault tolerance approach takes advantage of the redundant resources in the cloud environment, and makes the system more robust by masking faults instead of removing them.
Cloud computing platforms typically prefer to build reliability into the software. The software should be designed for failure and assumes that components will misbehave/fail or go away from time to time. Reliability should be built into application and as well as data. I.e. within the component or external module should monitor the service components and provide/execute recovery process. Multiple copies of data are maintained such that if you lose any individual machine the system continues to function (in the same way that if you lose a disk in a RAID array the service is uninterrupted). Large scale services will ideally also replicate data in multiple locations, such that if a rack, row of racks or even an entire datacenter were to fail then the service would still be uninterrupted
Load balancer in scalable architecture
29/06/14 15:34
In any SaaS or web application, incoming traffic from end-user, normally hit a load balancer as the first tier. The role load balancer is to balance the load of the request to next lower tier. There are two types of load balancers such as software-base or hardware based. Most load balancers provide different rules for distributing the load. Following are two of the most common options available.
- Round Robin: With round robin routing, the load balancer distributes inbound requests one at a time to an application server for processing, one after another. Provided that most requests can be serviced in an approximately even amount of time, this method results in a relatively well-balanced distribution of work across the available cluster of application servers.The drawback of this approach is that each individual transaction or request, even if it is from the same user session, will potentially go to a different application server for processing.
- Sticky Routing: When a load balancer implements sticky routing, the intent is to process all transactions or requests for a given user session by the same application server. In other words, when a user logs in, an application server is selected for processing by the load balancer. All subsequent requests for that user are then routed to the original application server for processing. This allows the application to retain session state in the application server, that is, information about the user and their actions as they continue to work in their session.Sticky routing is very useful in some scenarios, for example tracking a secure connection for the user without the need of authenticating repeatedly with each individual request (potentially a very expensive operation). The session state can also yield a better experience for the end user, by utilizing the session history of actions or other information about the user to tailor application responses.Given that the load balancer normally stores only information about the user connection and the assigned application server for the connection, sticky routing still meets the definition of a stateless component.
Cloud Modernization Process - Mistakes could be
27/06/14 00:45
Integrating legacy systems with cloud-based applications is a complex matter with ample room for error. The most frequent, overpriced, poorly functioning and even damaging mistakes businesses make include:
Mistake #1. Replacing the whole system:
Some enterprises choose to avoid the challenges of integration by creating a new system that replaces the full functionality of the old one. This is the most costly, difficult, and risk-prone option, but it does offer a long-term solution and may provide a system that is sufficiently agile to respond to changing business needs. Despite that potential pay-off, complete replacement requires a large, up-front investment for development, poses difficulties in duplicating behaviour of the legacy system, and increases the risk of complete software project failure.
Mistake #2. Wrapping existing legacy applications:
Often, organizations decide to wrap their legacy assets in shiny, more modern interfaces. These interfaces allow the use of a more flexible service-orientated architecture (SOA) approach, but they do not actually help make the system more flexible or easier to maintain. Certainly, wrapping allows increased access to the legacy system by other systems and the potential to replace individual parts on a piecemeal basis.
Although wrapping presents a modest up-front cost and relatively low risk, it fails to solve the core problem of legacy systems; enterprises still need to maintain outdated assets and still suffer from a lack of agility. To make matters worse, the look and feel of the wrappers are rarely elegant and quickly become dated themselves.
Mistake #3. Giving up and living with what you have:
Integration is difficult, and perhaps it shouldn’t be surprising that so many IT leaders go down this road. Despite the appearance of avoiding risk by avoiding change, giving up does not offer any hope of alleviating the legacy problem and provides only stagnation. Living with what you have frees you from up-front costs, but it denies you the ability to reduce maintenance expenses, increase operational efficiencies, or increase business agility that could boost your enterprise’s competitive advantage.
Mistake #4. Having the IT team create the utilities necessary to link individual applications:
This scenario occurs frequently but generally for a short time. Enterprises quickly discover that manually writing interfaces to accommodate obsolete platforms and programming languages is resource-intensive and prone to error.
Mistake #5: Implementing highly complex middleware solutions:
When considering a cloud integration platform, be sure there are not too many moving parts. If the middleware platform itself is so complex that you have to choose from among dozens of different products and then integrate the middleware to itself first before you can even begin to integrate your legacy applications to the cloud, you have a problem.If middleware requires the use of one or more programming or scripting language, you have another problem. A unified integration platform will simplify legacy application integration with the cloud.
Mistake #1. Replacing the whole system:
Some enterprises choose to avoid the challenges of integration by creating a new system that replaces the full functionality of the old one. This is the most costly, difficult, and risk-prone option, but it does offer a long-term solution and may provide a system that is sufficiently agile to respond to changing business needs. Despite that potential pay-off, complete replacement requires a large, up-front investment for development, poses difficulties in duplicating behaviour of the legacy system, and increases the risk of complete software project failure.
Mistake #2. Wrapping existing legacy applications:
Often, organizations decide to wrap their legacy assets in shiny, more modern interfaces. These interfaces allow the use of a more flexible service-orientated architecture (SOA) approach, but they do not actually help make the system more flexible or easier to maintain. Certainly, wrapping allows increased access to the legacy system by other systems and the potential to replace individual parts on a piecemeal basis.
Although wrapping presents a modest up-front cost and relatively low risk, it fails to solve the core problem of legacy systems; enterprises still need to maintain outdated assets and still suffer from a lack of agility. To make matters worse, the look and feel of the wrappers are rarely elegant and quickly become dated themselves.
Mistake #3. Giving up and living with what you have:
Integration is difficult, and perhaps it shouldn’t be surprising that so many IT leaders go down this road. Despite the appearance of avoiding risk by avoiding change, giving up does not offer any hope of alleviating the legacy problem and provides only stagnation. Living with what you have frees you from up-front costs, but it denies you the ability to reduce maintenance expenses, increase operational efficiencies, or increase business agility that could boost your enterprise’s competitive advantage.
Mistake #4. Having the IT team create the utilities necessary to link individual applications:
This scenario occurs frequently but generally for a short time. Enterprises quickly discover that manually writing interfaces to accommodate obsolete platforms and programming languages is resource-intensive and prone to error.
Mistake #5: Implementing highly complex middleware solutions:
When considering a cloud integration platform, be sure there are not too many moving parts. If the middleware platform itself is so complex that you have to choose from among dozens of different products and then integrate the middleware to itself first before you can even begin to integrate your legacy applications to the cloud, you have a problem.If middleware requires the use of one or more programming or scripting language, you have another problem. A unified integration platform will simplify legacy application integration with the cloud.
Enabling two-factor authentication for cloud applications
06/03/14 23:48
Two-factor authentication provide more security to make sure your accounts don't get hacked. Passwords, unfortunately, aren't as secure as they used to be. Having strong password may not help also. Humans are the weakest link and string password can be compromised. Two-factor authentication solves this problem and this is a simple feature that asks for more than just your password. It requires both "something you know" (like a password) and "something you have" (like your phone). After you enter your password, you'll get a second code sent to your phone, and only after you enter it will you get into your account. Currently, a lot of sites have recently implemented it, including many of social sites, business applications, etc. Here are some services that support two-factor authentication.
There are third party vendors such as Duo Web, and Authy provide REST API to enable your web applications as well. Evan Hanh List have more information on how to enable/integrate them.
- Google/Gmail: Google's two-factor authentication sends you a 6-digit code via text message when you attempt to log in from a new machine.
- Apple: Apple's two-factor authentication sends you a 4-digit code via text message or Find My iPhone notifications when you attempt to log in from a new machine.
- Facebook: Facebook's two-factor authentication, called "Login Approvals," sends you a 6-digit code via text message when you attempt to log in from a new machine.
- Twitter: Twitter's two-factor authentication sends you a 6-digit code via text message when you attempt to log in from a new machine.
- Dropbox: Dropbox's two-factor authentication sends you a 6-digit code via text message when you attempt to log in from a new machine.
- Evernote: Free Evernote users will need to use an authenticator app like Google Authenticator for Android, iOS, and BlackBerry, though premium users can also receive a code via text message to log into a new machine.
- PayPal: PayPal's two-factor authentication sends you a 6-digit code via text message when you attempt to log in from a new machine.
- Yahoo! Mail: Yahoo's two-factor authentication sends you a 6-digit code via text message when you attempt to log in from a new machine.
- Amazon Web Services: Amazon's web services, like Amazon S3 or Glacier storage, support two-factor authentication via authenticator apps, like the Google Authenticator app for Android, iOS, and BlackBerry.
- LinkedIn: LinkedIn's two-factor authentication sends you a 6-digit code via text message when you attempt to log in from a new machine.
- WordPress: WordPress supports two-factor authentication via the Google Authenticator app for Android, iOS, and BlackBerry.
There are third party vendors such as Duo Web, and Authy provide REST API to enable your web applications as well. Evan Hanh List have more information on how to enable/integrate them.
Cloud Characteristics
26/01/14 20:03
The NIST Draft – Cloud Computing Synopsis and Recommendations defines Cloud characteristics as:
• On-demand self-service
• Broad network access
• Resource pooling
• Rapid elasticity
• Measured service
How do these characteristics influence run-time behavior and determine whether PaaS offerings are cloud washed or cloud native?
Measured service or pay per use
The first Cloud characteristic, measured service, enables pay-as-you-go consumption models and subscription to metered services. Resource usage is monitored, and the system generates bills based on a charging model. To close the perception gap between business end-users and IT teams, the Cloud solution should bill for business value or business metrics instead of billing for IT resources. Business end-users do not easily correlate business value with an invoice for CPU time, network I/O, or data storage bytes. In contrast, business focused IT teams communicate value and charges based on number of users, processed forms, received marketing pieces, or sales transactions. A cloud native PaaS supports monitoring, metering, and billing based on business oriented entities.
Rapid Elasticity
A stateful monolithic application server cluster connected to a relational database does not efficiently scale with rapid elastically. Dynamic discoverability and rapid provisioning can instantiate processing and message nodes across a flexible and distributed topology. Applications exposing stateless services (or where state is transparently cached and available to instances) will seamlessly expand and contract to execute on available resources. A cloud native PaaS will interoperate with cloud management components to coordinate spinning up and tearing down instances based on user, message, and business transaction load in addition to raw infrastructure load (i.e. CPU and memory utilization).
Resource Pooling
Development and operation teams are familiar with resource pooling. Platform environments commonly pool memory, code libraries, database connections, and resource bundles for use across multiple requests or application instances. But because hardware isolation has traditionally been required to enforce quality of service and security, hardware resource utilization has traditionally been extremely low (~5-15%). While virtualization is often used to increase application-machine density and raise machine utilization, virtualization efforts often result in only (~50-60%) utilization. With PaaS level multi-tenancy, deterministic performance, and application container level isolation, an organization could possible shrink it’s hardware footprint by half. Sophisticated PaaS environments allocate resources and limit usage based on policy and context. The environment may limit usage by throttling messages, time slicing resource execution, or queuing demand.
Integration and SOA run-time infrastructure delivers effective resource pools. As teams start to pool resources beyond a single Cloud environment, integration is required to merge disparate identities, entitlements, policies, and resource models. As teams start to deliver application capabilities as Cloud services, a policy aware SOA run-time infrastructure pools service instances, manages service instance lifecycle, and mediates access.
On-demand self-service
On-demand self-service requires infrastructure automation to flexibly assign workloads and decrease provisioning periods. If teams excessively customize an environment, they will increase time to market, lower resource pooling, and create a complex environment, which is difficult to manage and maintain. Users should predominantly subscribe to standard platform service offerings, and your team should minimize exceptions. Cloud governance is an important Cloud strategy component.
• On-demand self-service
• Broad network access
• Resource pooling
• Rapid elasticity
• Measured service
How do these characteristics influence run-time behavior and determine whether PaaS offerings are cloud washed or cloud native?
Measured service or pay per use
The first Cloud characteristic, measured service, enables pay-as-you-go consumption models and subscription to metered services. Resource usage is monitored, and the system generates bills based on a charging model. To close the perception gap between business end-users and IT teams, the Cloud solution should bill for business value or business metrics instead of billing for IT resources. Business end-users do not easily correlate business value with an invoice for CPU time, network I/O, or data storage bytes. In contrast, business focused IT teams communicate value and charges based on number of users, processed forms, received marketing pieces, or sales transactions. A cloud native PaaS supports monitoring, metering, and billing based on business oriented entities.
Rapid Elasticity
A stateful monolithic application server cluster connected to a relational database does not efficiently scale with rapid elastically. Dynamic discoverability and rapid provisioning can instantiate processing and message nodes across a flexible and distributed topology. Applications exposing stateless services (or where state is transparently cached and available to instances) will seamlessly expand and contract to execute on available resources. A cloud native PaaS will interoperate with cloud management components to coordinate spinning up and tearing down instances based on user, message, and business transaction load in addition to raw infrastructure load (i.e. CPU and memory utilization).
Resource Pooling
Development and operation teams are familiar with resource pooling. Platform environments commonly pool memory, code libraries, database connections, and resource bundles for use across multiple requests or application instances. But because hardware isolation has traditionally been required to enforce quality of service and security, hardware resource utilization has traditionally been extremely low (~5-15%). While virtualization is often used to increase application-machine density and raise machine utilization, virtualization efforts often result in only (~50-60%) utilization. With PaaS level multi-tenancy, deterministic performance, and application container level isolation, an organization could possible shrink it’s hardware footprint by half. Sophisticated PaaS environments allocate resources and limit usage based on policy and context. The environment may limit usage by throttling messages, time slicing resource execution, or queuing demand.
Integration and SOA run-time infrastructure delivers effective resource pools. As teams start to pool resources beyond a single Cloud environment, integration is required to merge disparate identities, entitlements, policies, and resource models. As teams start to deliver application capabilities as Cloud services, a policy aware SOA run-time infrastructure pools service instances, manages service instance lifecycle, and mediates access.
On-demand self-service
On-demand self-service requires infrastructure automation to flexibly assign workloads and decrease provisioning periods. If teams excessively customize an environment, they will increase time to market, lower resource pooling, and create a complex environment, which is difficult to manage and maintain. Users should predominantly subscribe to standard platform service offerings, and your team should minimize exceptions. Cloud governance is an important Cloud strategy component.