Data pipeline
Setup ActiveMQ, Zookeeper, and Replicated LevelDB running in JDK 8 and CentOS
22/08/14 11:53
This guide describes the step-by-step guide to setup ActiveMQ to use replicated LevelDB persistence with Zookeeper. CentOS environment is used for servers. Zookeeper is used to replicate the LevelDB to support Master/Slave activeMQs. Three VMware instances are used with 2 Core processes, 2G RAM and 20G disk space. For simplicity, stop the IPtable service (firewall) in CentOS. If IPTable is required then you need to open set of ports. List of port numbers are included in pre-setup work section.
Overview
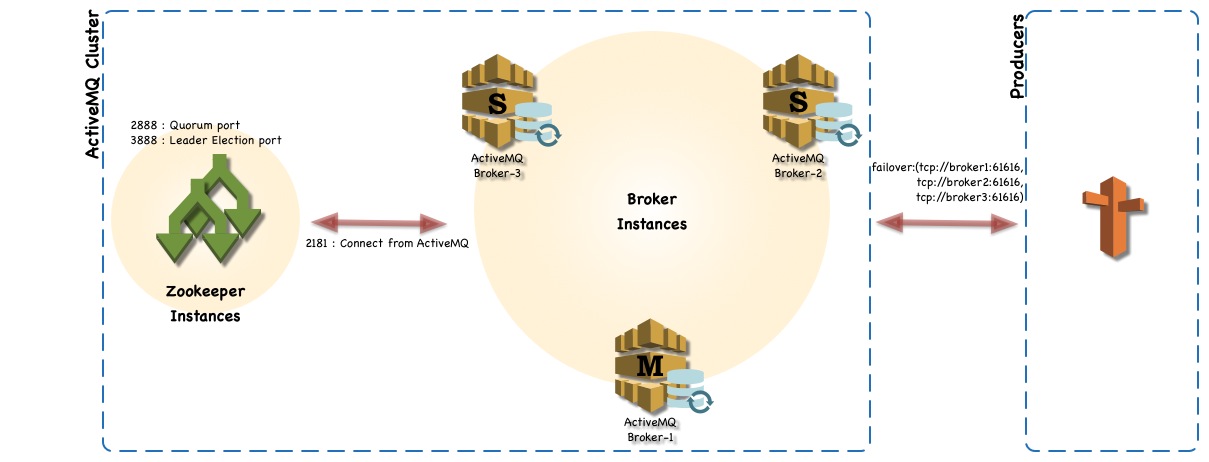
ActiveMQ cluster environment includes following
1 Three VM instances with CentOS os AND JDK 8
2 Three ActiveMQ instances.
3 Three Zookeeper instances.
Pre-install
Following ports are required to open in Iptables host firewall.
Installation
Java JDK
Zookeeper
Download activemq distribution from http://apache.mirror.nexicom.net/activemq/5.10.0/apache-activemq-5.10.0-bin.tar.gz
My approach was to get the software setup on a single VM instance in VM Ware fusion, and create two more clones to have three servers. I have named the instances as messageq1, messageq2, and messageq3. After starting instances confirm the myid file and IP address in the zoo.cfg are setup properly with new instance’s ip address.
After configured everything
No IOExceptionHandler registered, ignoring IO exception | org.apache.activemq.broker.BrokerService | LevelDB IOExcepti
on handler.
java.io.IOException: com.google.common.base.Objects.firstNonNull(Ljava/lang/Object;Ljava/lang/Object Ljava/lang/Object;
Ljava/lang/Object;
at org.apache.activemq.util.IOExceptionSupport.create(IOExceptionSupport.java:39)[activemq-client-5.10.0.jar:5.10.0]
at org.apache.activemq.leveldb.LevelDBClient.might_fail(LevelDBClient.scala:552)[activemq-leveldb-store-5.10.0.jar:5.10.0]
at org.apache.activemq.leveldb.LevelDBClient.replay_init(LevelDBClient.scala:657)[activemq-leveldb-store-5.10.0.jar:5.10.0]
at org.apache.activemq.leveldb.LevelDBClient.start(LevelDBClient.scala:558)[activemq-leveldb-store-5.10.0.jar:5.10.0]
at org.apache.activemq.leveldb.DBManager.start(DBManager.scala:648)[activemq-leveldb-store-5.10.0.jar:5.10.0]
at org.apache.activemq.leveldb.LevelDBStore.doStart(LevelDBStore.scala:235)[activemq-leveldb-store-5.10.0.jar:5.10.0]
at org.apache.activemq.leveldb.replicated.MasterLevelDBStore.doStart(MasterLevelDBStore.scala:110)[activemq-leveldb-store-5.10.0.jar:5.10.0]
at org.apache.activemq.util.ServiceSupport.start(ServiceSupport.java:55)[activemq-client-5.10.0.jar:5.10.0]
at org.apache.activemq.leveldb.replicated.ElectingLevelDBStore$$anonfun$start_master$1.apply$mcV$sp(ElectingLevelDBStore.scala:226)[activemq-lev
eldb-store-5.10.0.jar:5.10.0]
at org.fusesource.hawtdispatch.package$$anon$4.run(hawtdispatch.scala:330)[hawtdispatch-scala-2.11-1.21.jar:1.21]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)[:1.8.0_20]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)[:1.8.0_20]
After going through tickets in activeMQ found following ticket has been reported https://issues.apache.org/jira/browse/AMQ-5225. Workaround described in the ticket will solve the issue. The work around for this issue,
To confirm ActiveMQ listening for request
◦ In master, check with netstat -an | grep 61616 and confirm the port is in listen mode.
◦ In slaves, you can run netstat -an | grep 6161 and output should show you slave binding port 61619
Post-Install
◦ For Zookeeper, set the Java heap size. This is very important to avoid swapping, which will seriously degrade ZooKeeper performance. To determine the correct value, use load tests, and make sure you are well below the usage limit that would cause you to swap. Be conservative - use a maximum heap size of 3GB for a 4GB machine.
◦ Increase the open file number to support 51200. E.g: limit -n 51200.
◦ Review linux network setting parameters : http://www.nateware.com/linux-network-tuning-for-2013.html#.VA8pN2TCMxo
◦ Review ActiveMQ transports configuration settings : http://activemq.apache.org/configuring-transports.html
◦ Review ActiveMQ persistence configuration settings : http://activemq.apache.org/persistence.html
◦ Review zookeeper configuration settings : http://zookeeper.apache.org/doc/trunk/zookeeperAdmin.html#sc_configuration
Reference
◦ tickTime: the length of a single tick, which is the basic time unit used by ZooKeeper, as measured in milliseconds. It is used to regulate heartbeats, and timeouts. For example, the minimum session timeout will be two ticks.
◦ initLimit: Amount of time, in ticks , to allow followers to connect and sync to a leader. Increased this value as needed, if the amount of data managed by ZooKeeper is large.
◦ syncLimit: Amount of time, in ticks , to allow followers to sync with ZooKeeper. If followers fall too far behind a leader, they will be dropped.
◦ clientPort: The port to listen for client connections; that is, the port that clients attempt to connect to.
◦ dataDir: The location where ZooKeeper will store the in-memory database snapshots and, unless specified otherwise, the transaction log of updates to the database.
ActiveMQ configuration file from msgq1
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://activemq.apache.org/schema/core http://activemq.apache.org/schema/core/activemq-core.xsd">
file:${activemq.conf}/credentials.properties
directory=“~/Dev/server/activemq/data/leveldb"
hostname="192.168.163.160"/>
ZK Configuration file
tickTime=2000
initLimit=5
syncLimit=2
dataDir=/home/sthuraisamy/Dev/server/data/zk
clientPort=2181
server.1=192.168.163.160:2888:3888
server.2=192.168.163.161:2888:3888
server.3=192.168.163.162:2888:3888
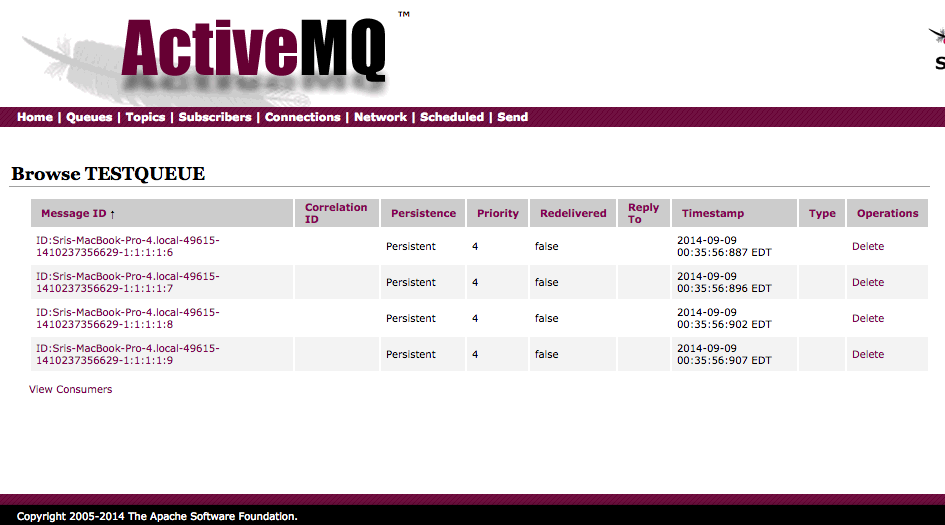
In ActiveMQ 5.10 web console you can view and delete the pending messages in a Queue
Overview
ActiveMQ cluster environment includes following
1 Three VM instances with CentOS os AND JDK 8
2 Three ActiveMQ instances.
3 Three Zookeeper instances.
Pre-install
Following ports are required to open in Iptables host firewall.
- Zookeeper
- 2181 – the port that clients will use to connect to the ZK ensemble
- 2888 – port used by ZK for quorum election
- 3888 – port used by ZK for leader election
- ActiveMQ
- 61616 – default Openwire port
- 8161 – Jetty port for web console
- 61619 – LevelDB peer-to-peer replication port for ActiveMQ slaves.
- To check Iptables status.
- service iptables status
- To stop iptables service
- service iptables save
- service iptables stop
- chkconfig iptables off
- To start again
- service iptables start
- chkconfig iptables on
- Setup proper hostname, edit following files
- Update HOSTNAME value in /etc/sysconfig/network : E.g: HOSTNAME=msgq1.dev.int
- Add host name with IP address of the machine in /etc/hosts: E.g: 192.168.163.160 msgq1.dev.int msgqa1
- Restart the instance and repeat same process each instances.
Installation
Java JDK
- Download JDK 8 from http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
- Extract JdK-8*.tar.gz to a folder of your choice (I used ~/Dev/server). This will create folder ~/Dev/server/jdk1.8.0_20.
- Set up JAVA_HOME directory.
- To setup for all users edit /etc/profile and add following line export JAVA_HOME=HOME_DIR/Dev/server/jdk1.8.0_20.
Zookeeper
- Download zookeeper from site http://zookeeper.apache.org/
- Extract the file into your folder of your choice. I have used ~/Dev/server/
- Create soft link zookeeper for extracted directory.
- For reliable ZooKeeper service, the ZK should be deployed in a cluster mode knows as ensemble. As long as a majority of the ensemble are up, the service will be available.
- Goto conf directory and create zookeeper configuration directory.
- cd
/conf - Copy zoo_sample.cfg to zoo.cfg
- Make sure the file has following lines
- tickTime=2000initLimit=5
syncLimit=2
dataDir=~/Dev/server/data/zk
clientPort=2181
- tickTime=2000initLimit=5
- Add following lines into zoo.cfg at the end.
- server.1=zk1_IPADDRESS:2888:3888
server.2=zk2_IPADDRESS:2888:3888
server.3=zk3_IPADDRESS:2888:3888
- server.1=zk1_IPADDRESS:2888:3888
- zk1, zk2 & zk3 are IP addresses for the ZK servers.
- Port 2181 is used to communicate with client
- Port 2888 is used by peer ZK servers to communicate among themselves (Quorum port)
- Port 3888 is used for leader election (Leader election port).
- The last three lines of the server.id=host:port:port format specifies that there are three nodes in the ensemble. In an ensemble, each ZooKeeper node must have a unique ID between 1 and 255. This ID is defined by creating a file named myid in the dataDir directory of each node. For example, the node with the ID 1 (server.1=zk1:2888:3888) will have a myid file at /home/sthuraisamy/Dev/server/data/zk with the text 1 inside it.
- Create myid file in data directory for zk1 ( server.1) and for other ZK servers as 2 & 3.
- echo 1 > myid
Download activemq distribution from http://apache.mirror.nexicom.net/activemq/5.10.0/apache-activemq-5.10.0-bin.tar.gz
- Extract the file into your folder of your choice. I have used ~/Dev/server/
- Create soft link activemq for extracted directory.
- Do following
- cd
/bin
- cd
- chmod 755 activemq
/bin/activemq start
- To confirm the activemq is listening on port 61616 or check the log file and confirm port listening messages are populated.
- netstat -an|grep 61616
- In activemq config file, following bean classes define the settings
- PropertyPlaceholderConfigurer
- Credentials
- Broker section
- constantPendingMessageLimitStrategy: limit the number of messages to be keep in memory for slow consumers.
- Other settings to handle slower consumers, refer http://activemq.apache.org/slow-consumer-handling.html
- Persistence adapter to define the storage to keep the messages.
- For better performance
- Use NIO : Refer http://activemq.apache.org/configuring-transports.html#ConfiguringTransports-TheNIOTransport
- Replicated LevelDB store using Zookeeper http://activemq.apache.org/replicated-leveldb-store.html
- The settings need to be done in ActiveMQ after zookeeper is setup. Add following lines into conf/activemq.xml
- hostname should be assigned with separate IP address for each instance.
My approach was to get the software setup on a single VM instance in VM Ware fusion, and create two more clones to have three servers. I have named the instances as messageq1, messageq2, and messageq3. After starting instances confirm the myid file and IP address in the zoo.cfg are setup properly with new instance’s ip address.
After configured everything
- Start the Zookeeper instances in all three nodes :
/bin/zk_Server.sh start - Start the activeMQ instances in all three nodes :
/bin/activemq start - In my setup when I start the first node I didn’t find any issue. After I have started the second node, I found exception in the log file.
No IOExceptionHandler registered, ignoring IO exception | org.apache.activemq.broker.BrokerService | LevelDB IOExcepti
on handler.
java.io.IOException: com.google.common.base.Objects.firstNonNull(Ljava/lang/Object;Ljava/lang/Object
at org.apache.activemq.util.IOExceptionSupport.create(IOExceptionSupport.java:39)[activemq-client-5.10.0.jar:5.10.0]
at org.apache.activemq.leveldb.LevelDBClient.might_fail(LevelDBClient.scala:552)[activemq-leveldb-store-5.10.0.jar:5.10.0]
at org.apache.activemq.leveldb.LevelDBClient.replay_init(LevelDBClient.scala:657)[activemq-leveldb-store-5.10.0.jar:5.10.0]
at org.apache.activemq.leveldb.LevelDBClient.start(LevelDBClient.scala:558)[activemq-leveldb-store-5.10.0.jar:5.10.0]
at org.apache.activemq.leveldb.DBManager.start(DBManager.scala:648)[activemq-leveldb-store-5.10.0.jar:5.10.0]
at org.apache.activemq.leveldb.LevelDBStore.doStart(LevelDBStore.scala:235)[activemq-leveldb-store-5.10.0.jar:5.10.0]
at org.apache.activemq.leveldb.replicated.MasterLevelDBStore.doStart(MasterLevelDBStore.scala:110)[activemq-leveldb-store-5.10.0.jar:5.10.0]
at org.apache.activemq.util.ServiceSupport.start(ServiceSupport.java:55)[activemq-client-5.10.0.jar:5.10.0]
at org.apache.activemq.leveldb.replicated.ElectingLevelDBStore$$anonfun$start_master$1.apply$mcV$sp(ElectingLevelDBStore.scala:226)[activemq-lev
eldb-store-5.10.0.jar:5.10.0]
at org.fusesource.hawtdispatch.package$$anon$4.run(hawtdispatch.scala:330)[hawtdispatch-scala-2.11-1.21.jar:1.21]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)[:1.8.0_20]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)[:1.8.0_20]
After going through tickets in activeMQ found following ticket has been reported https://issues.apache.org/jira/browse/AMQ-5225. Workaround described in the ticket will solve the issue. The work around for this issue,
- remove pax-url-aether-1.5.2.jar from lib directory
- comment out the log query section
To confirm ActiveMQ listening for request
◦ In master, check with netstat -an | grep 61616 and confirm the port is in listen mode.
◦ In slaves, you can run netstat -an | grep 6161 and output should show you slave binding port 61619
Post-Install
◦ For Zookeeper, set the Java heap size. This is very important to avoid swapping, which will seriously degrade ZooKeeper performance. To determine the correct value, use load tests, and make sure you are well below the usage limit that would cause you to swap. Be conservative - use a maximum heap size of 3GB for a 4GB machine.
◦ Increase the open file number to support 51200. E.g: limit -n 51200.
◦ Review linux network setting parameters : http://www.nateware.com/linux-network-tuning-for-2013.html#.VA8pN2TCMxo
◦ Review ActiveMQ transports configuration settings : http://activemq.apache.org/configuring-transports.html
◦ Review ActiveMQ persistence configuration settings : http://activemq.apache.org/persistence.html
◦ Review zookeeper configuration settings : http://zookeeper.apache.org/doc/trunk/zookeeperAdmin.html#sc_configuration
Reference
◦ tickTime: the length of a single tick, which is the basic time unit used by ZooKeeper, as measured in milliseconds. It is used to regulate heartbeats, and timeouts. For example, the minimum session timeout will be two ticks.
◦ initLimit: Amount of time, in ticks , to allow followers to connect and sync to a leader. Increased this value as needed, if the amount of data managed by ZooKeeper is large.
◦ syncLimit: Amount of time, in ticks , to allow followers to sync with ZooKeeper. If followers fall too far behind a leader, they will be dropped.
◦ clientPort: The port to listen for client connections; that is, the port that clients attempt to connect to.
◦ dataDir: The location where ZooKeeper will store the in-memory database snapshots and, unless specified otherwise, the transaction log of updates to the database.
ActiveMQ configuration file from msgq1
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://activemq.apache.org/schema/core http://activemq.apache.org/schema/core/activemq-core.xsd">
directory=“~/Dev/server/activemq/data/leveldb"
hostname="192.168.163.160"/>
ZK Configuration file
tickTime=2000
initLimit=5
syncLimit=2
dataDir=/home/sthuraisamy/Dev/server/data/zk
clientPort=2181
server.1=192.168.163.160:2888:3888
server.2=192.168.163.161:2888:3888
server.3=192.168.163.162:2888:3888
In ActiveMQ 5.10 web console you can view and delete the pending messages in a Queue
Streaming Data
21/08/14 00:49
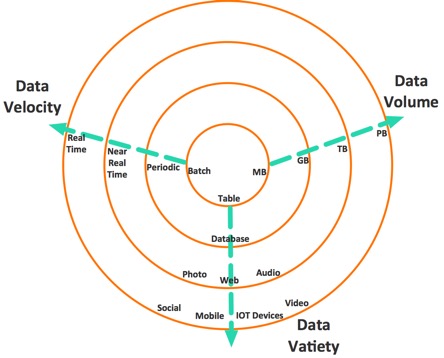
BigData is a collection of data set so large and complex that it becomes difficult to process using on-hand database management tools or traditional applications. The datasets not only contain structured datasets, but also include unstructured datasets. Big data has three characteristics:
The diagram explains the characteristics.
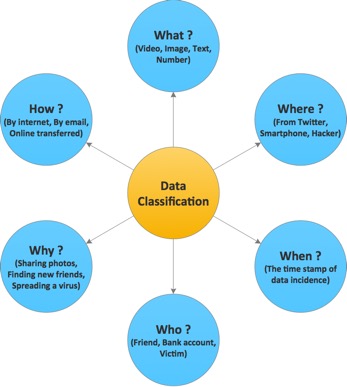
Recently, more and more is getting easily available as streams. The stream data item can be classified into 5Ws data dimensions.
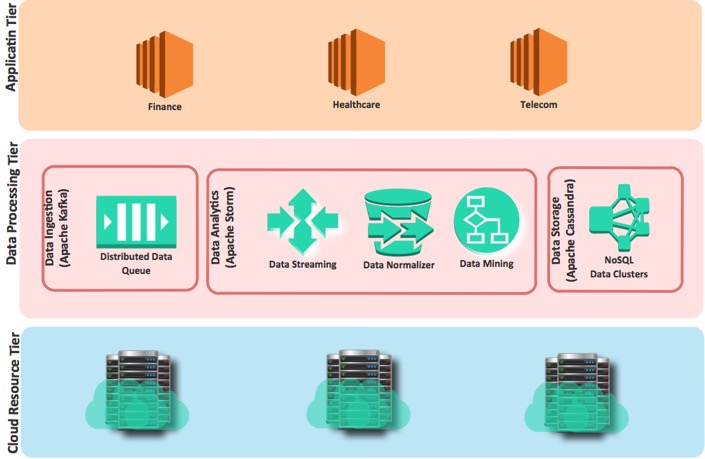
Conventional data processing technologies are now unable to process these kind of volume data within a tolerable elapsed time. In-memory databases also have certain key problems such as larger data size may not fit into memory, moving all data sets into centralized machine is too expensive. To process data as they arrive, the paradigm has changed from the conventional “one-shot” data processing approach to elastic and virtualized datacenter cloud-based data processing frameworks that can mine continuos, high-volume, open-ended data streams.
The framework contains three main components.
Following diagram explain these components.
- Volume
- Velocity.
- Variety.
The diagram explains the characteristics.
Recently, more and more is getting easily available as streams. The stream data item can be classified into 5Ws data dimensions.
- What the data is? Video, Image, Text, Number
- Where the data came from? From twitter, Smart phone, Hacker
- When the data occurred? The timestamp of data incidence.
- Who received the data? Friend, Bank account, victim
- Why the data occurred? Sharing photos, Finding new friends, Spreading a virus
- How the data was transferred? By Internet, By email, Online transferred
Conventional data processing technologies are now unable to process these kind of volume data within a tolerable elapsed time. In-memory databases also have certain key problems such as larger data size may not fit into memory, moving all data sets into centralized machine is too expensive. To process data as they arrive, the paradigm has changed from the conventional “one-shot” data processing approach to elastic and virtualized datacenter cloud-based data processing frameworks that can mine continuos, high-volume, open-ended data streams.
The framework contains three main components.
- Data Ingestion: Accepts the data from multiple sources such as social networks, online services, etc.
- Data Analytics: Consist many systems to read, analyze, clean and normalize.
- Data Storage: Provide to store and index data sets.
Following diagram explain these components.
ActiveMQ HA Tunning
15/07/14 22:52
Performance is based on following factors
The possible bottlenecks are
Async publishing
When an ActiveMQ message producer sends a non-persistent message, its dispatched asynchronously (fire and forget) - but for persistent messages, the publisher will block until it gets a notification that the message has been processed (saved to the store - queued to be dispatched to any active consumers etc) by the broker. messages are dispatched with delivery mode set to be persistent by default (which is required by the JMS spec). So if you are sending messages on a Topic, the publisher will block by default (even if there are no durable subscribers on the topic) until the broker has returned a notification. So if you looking for good performance with topic messages, either set the delivery mode on the publisher to be non-persistent, or set the useAsyncSend property on the ActiveMQ ConnectionFactory to be true.
Pre-fetch sizes for Consumer
ActiveMQ will push as many messages to the consumer as fast as possible, where they will be queued for processing by an ActiveMQ Session. The maximum number of messages that ActiveMQ will push to a Consumer without the Consumer processing a message is set by the pre-fetch size. You can improve throughput by running ActiveMQ with larger pre-fetch sizes. Pre-fetch sizes are determined by the ActiveMQPrefetchPolicy bean, which is set on the ActiveMQ ConnectionFactory.
queue -> 1000
queue browser -> 500
topic -> 32767
durable topic -> 1000
Optimized acknowledge
When consuming messages in auto acknowledge mode (set when creating the consumers' session), ActiveMQ can acknowledge receipt of messages back to the broker in batches (to improve performance). The batch size is 65% of the prefetch limit for the Consumer. Also if message consumption is slow the batch will be sent every 300ms. You switch batch acknowledgment on by setting the optimizeAcknowledge property on the ActiveMQ ConnectionFactory to be true
Straight through session consumption
By default, a Consumer's session will dispatch messages to the consumer in a separate thread. If you are using Consumers with auto acknowledge, you can increase throughput by passing messages straight through the Session to the Consumer by setting the alwaysSessionAsync property on the ActiveMQ ConnectionFactory to be false
File based persistence
file based persistence store that can be used to increase throughput for the persistent messages
Performance test tools
- The network topology
- Transport protocols used
- Quality of service
- Hardware, network, JVM and operating system
- Number of producers, number of consumers
- Distribution of messages across destinations along with message size
The possible bottlenecks are
- Overall system
- Network latencies
- Disk IO
- Threading overheads
- JVM optimizations
Async publishing
When an ActiveMQ message producer sends a non-persistent message, its dispatched asynchronously (fire and forget) - but for persistent messages, the publisher will block until it gets a notification that the message has been processed (saved to the store - queued to be dispatched to any active consumers etc) by the broker. messages are dispatched with delivery mode set to be persistent by default (which is required by the JMS spec). So if you are sending messages on a Topic, the publisher will block by default (even if there are no durable subscribers on the topic) until the broker has returned a notification. So if you looking for good performance with topic messages, either set the delivery mode on the publisher to be non-persistent, or set the useAsyncSend property on the ActiveMQ ConnectionFactory to be true.
Pre-fetch sizes for Consumer
ActiveMQ will push as many messages to the consumer as fast as possible, where they will be queued for processing by an ActiveMQ Session. The maximum number of messages that ActiveMQ will push to a Consumer without the Consumer processing a message is set by the pre-fetch size. You can improve throughput by running ActiveMQ with larger pre-fetch sizes. Pre-fetch sizes are determined by the ActiveMQPrefetchPolicy bean, which is set on the ActiveMQ ConnectionFactory.
queue -> 1000
queue browser -> 500
topic -> 32767
durable topic -> 1000
Optimized acknowledge
When consuming messages in auto acknowledge mode (set when creating the consumers' session), ActiveMQ can acknowledge receipt of messages back to the broker in batches (to improve performance). The batch size is 65% of the prefetch limit for the Consumer. Also if message consumption is slow the batch will be sent every 300ms. You switch batch acknowledgment on by setting the optimizeAcknowledge property on the ActiveMQ ConnectionFactory to be true
Straight through session consumption
By default, a Consumer's session will dispatch messages to the consumer in a separate thread. If you are using Consumers with auto acknowledge, you can increase throughput by passing messages straight through the Session to the Consumer by setting the alwaysSessionAsync property on the ActiveMQ ConnectionFactory to be false
File based persistence
file based persistence store that can be used to increase throughput for the persistent messages
Performance test tools
- http://activemq.apache.org/activemq-performance-module-users-manual.html
- http://activemq.apache.org/jmeter-performance-tests.html
Kafka Design
05/07/14 01:20
Existing messaging systems have too much complexity created the limitations in performance, scaling and managing. To overcome this issue, LinkedIn (www.linkedin.com) decided to build Kafka to address their need for monitoring activity stream data and operational metrics such as CPU, I/O usage, and request timings.
While developing Kafka, the main focus was to provide the following
In a very basic structure, a producer publishes messages to a Kafka topic, which is created on a Kafka broker acting as a Kafka server. Consumers then subscribe to the Kafka topic to get the messages.
Important Kafka design facts are as follows:
The above notes are taken from “Apache Kafka” Book.
While developing Kafka, the main focus was to provide the following
- An API for producers and consumers to support custom implementation
- Low overhead for network and storage with message persistence
- High throughput supporting millions of messages
- Distributed and highly scalable architecture
In a very basic structure, a producer publishes messages to a Kafka topic, which is created on a Kafka broker acting as a Kafka server. Consumers then subscribe to the Kafka topic to get the messages.
Important Kafka design facts are as follows:
- The fundamental backbone of Kafka is message caching and storing it on the filesystem. In Kafka, data is immediately written to the OS kernel page. Caching and flushing of data to the disk is configurable.
- Kafka provides longer retention of messages ever after consumption, allowing consumers to re-consume, if required.
- Kafka uses a message set to group messages to allow lesser network overhead.
- Unlike most of the messaging systems, where metadata of the consumed messages are kept at server level, in Kafka, the state of the consumed messages is maintained at consumer level. This also addresses issues such as:
- Loosing messages due to failure
- Multiple deliveries of the same message
- By default, consumers store the state in ZooKeeper, but Kafka also allows storing it within other storage systems used for Online Transaction Processing (OLTP) applications as well.
- In Kafka, producers and consumers work on the traditional push-and-pull model, where producers push the message to a Kafka broker and consumers pull the message from the broker.
- Kafka does not have any concept of a master and treats all the brokers as peers. This approach facilitates addition and removal of a Kafka broker at any point, as the metadata of brokers are maintained in ZooKeeper and shared with producers and consumers.
- In Kafka 0.7.x, ZooKeeper-based load balancing allows producers to discover the broker dynamically. A producer maintains a pool of broker connections, and constantly updates it using ZooKeeper watcher callbacks. But in Kafka 0.8.x, load balancing is achieved through Kafka metadata API and ZooKeeper can only be used to identify the list of available brokers.
- Producers also have an option to choose between asynchronous or synchronous mode for sending messages to a broker.
The above notes are taken from “Apache Kafka” Book.
Hadoop Platform Architecture
27/05/14 00:21
Hadoop platform contains following major modules
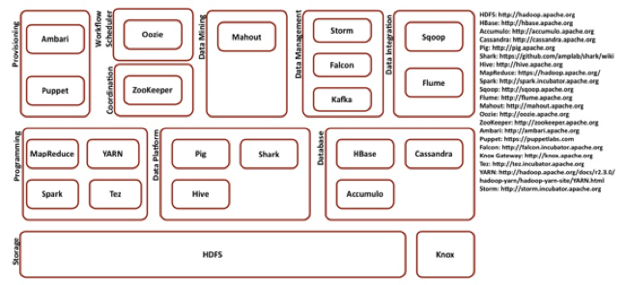
- Storage
- Programming
- Data Platform
- Database
- Provisioning
- Coordination
- Workflow Scheduler
- Data Mining
- Data Integration
Log Management with Flume
18/04/14 00:36
- Flume is a distributed, reliable, and available service for efficiently collecting, aggregating, and moving large amounts of log data. It has a simple and flexible architecture based on streaming data flows. It is robust and fault tolerant with tunnable reliability mechanisms and many failover and recovery mechanisms. The system is centrally managed and allows for intelligent dynamic management. It uses a simple extensible data model that allows for online analytic applications.
- Flume allows you to configure your Flume installation from a central point, without having to ssh into every machine, update a configuration variable and restart a daemon or two. You can start, stop, create, delete and reconfigure logical nodes on any machine running Flume from any command line in your network with the Flume jar available.
- Flume also has centralized liveness monitoring. We've heard a couple of stories of Scribe processes silently failing, but lying undiscovered for days until the rest of the Scribe installation starts creaking under the increased load. Flume allows you to see the health of all your logical nodes in one place (note that this is different from machine liveness monitoring; often the machine stays up while the process might fail).
- Flume supports three distinct types of reliability guarantees, allowing you to make tradeoffs between resource usage and reliability. In particular, Flume supports fully ACKed reliability, with the guarantee that all events will eventually make their way through the event flow.
- Flume's also really extensible - it's really easy to write your own source or sink and integrate most any system with Flume. If rolling your own is impractical, it's often very straightforward to have your applications output events in a form that Flume can understand (Flume can run Unix processes, for example, so if you can use shell script to get at your data, you're golden).
NoSQL Systems
03/02/14 21:53
These are so many NoSQL systems these days that it’s hard to get a quick overview of the major trade-offs involved when evaluating relational and non-relational systems in non-single server environments. There are three primary concerns must be balanced when choosing a data management.
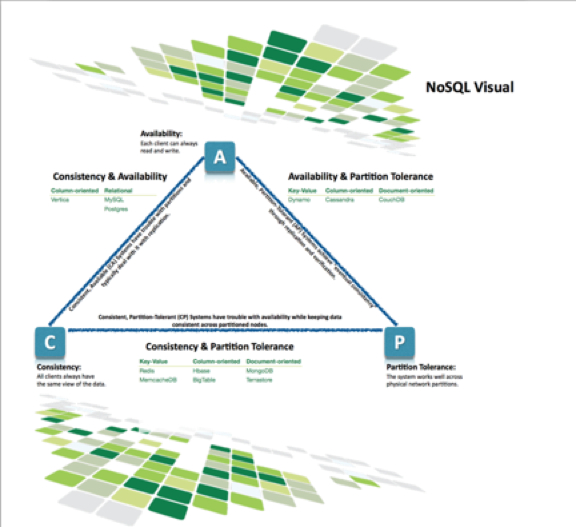
- Consistency means that each client always has the same view of the data.
- Availability means that all clients can always read and write.
- Partition tolerance means that the system works well across physical network partitions.